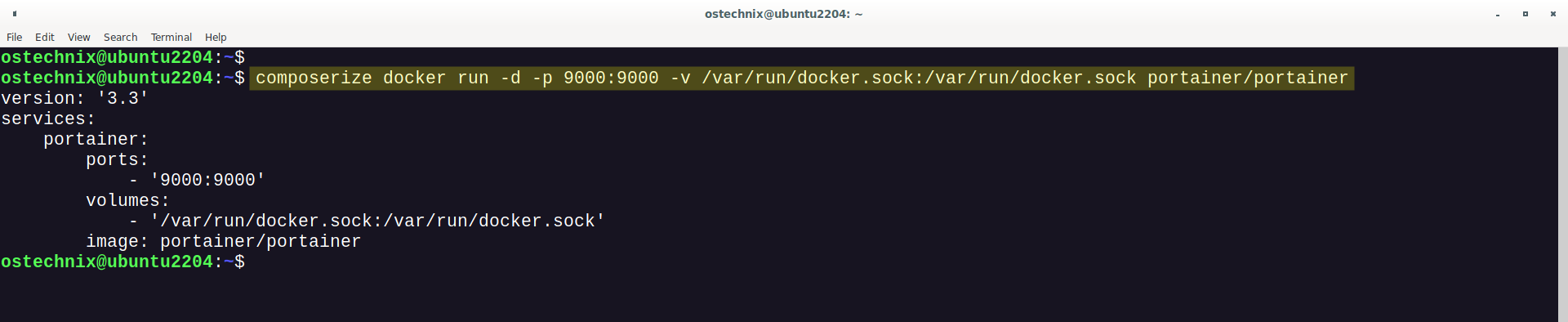
一、foreach 属性使用
<foreach collection="list" index="index" item="mchntCd" open="(" close=")" separator=",">
#{mchntCd}
</foreach>
- item: 集合中元素迭代时的别名,该参数为必选,通过别名进行取值
- index:在list和数组中,index是元素的序号,在map中,index是元素的key,非必填
- open: foreach代码的开始符号,一般是(和close=”)”合用。常用在in(),values()时。非必填
- separator:元素之间的分隔符,例如在in()的时候,separator=”,”会自动在元素中间用“,“隔开,避免手动输入逗号导致sql错误,如in(1,2,)这样。非必填
- close: foreach代码的关闭符号,一般是)和open=”(“合用。常用在in(),values()时。非必填
- collection: 要做foreach的对象,作为入参
- 传入是集合,也就是接口里面用的 List<String> nameList 那么 使用 collection = “list”
- 传入的是数组,接口里面 String[] namestrs ,那么 使用 collection = “array”
- 如果传入的是一个实体bean,实体bean里面有一个属性为 list<String> ids 那么collection = “ids ”,如果实体bean中对应ids是一个对象,ids 里面有一个属性为 List<Stirng> usernames,那么collection = “ids.usernames”
二、代码使用
1、实体类 list<String> mchntCds
mapper接口 —》 list方式mapper映射xml:int queryDiscDerateCount (List<String> mchntCds);
2、实体类 list<User> userlist,实体类中有 list 属性
实体类:
mapper映射xml:List<TMchntDerateInfoDto> getDiscDerateList (List<MchntDiscDerateDto> discDto);
3、数组 String[] params 用 array
mapper 接口mapper映射xml:int queryDiscDerateCount (String[] mchntCds);
4、传入的参数是实体类,并且实体中包含数组和集合
实体类:
mapper映射文件xmlList<UserVo> queryList (UserVo select);
5、传入多个list或者array,不使用实体进行封装。用注解@Params, collection使用到Param中定义的别名
mapper接口mapper映射文件xmlList<UserVo> queryList (@Param("idArray") Long[] array, @Param("clientIdList") List<Long> list);
6、map参数
当我们传入的参数为 Map<String,Objject>的时候,那么能不能正常使用 foreach呢,答案是肯定的,因为对象也是类似于map结构啊
-
/**
-
* map 获取数据
-
* @param map
-
* @return
-
*/
-
List<SysUser> getUserByIds (Map<String,Object> map);
-
-
-
-
// xml
-
<select id=“getUserByIds” resultMap=“BaseResultMap”>
-
select
-
<include refid=“Base_Column_List” />
-
from t_sys_user
-
where status = #{status}
-
and id in
-
<foreach collection=“ids” item=“id” open=“(“ close=“)” separator=“,”>
-
#{id}
-
</foreach>
-
</select>
实际调用:
-
@Test
-
public void testMapUsers() {
-
Map<String,Object> params = new HashMap<>();
-
params.put(“status”, “1”);
-
params.put(“ids”, Arrays.asList(1,2,3,4,5,6,7,8));
-
-
List<SysUser> all = sysUserDao.getUserByIds(params);
-
try {
-
System.out.println(new JsonMapper().writeValueAsString(all));
-
} catch (JsonProcessingException e) {
-
e.printStackTrace();
-
}
-
}
调用结果:

三、总结
1、mapper 接口中添加 @Param注解的场合,list,array将会失效;
2、使用了 @Param注解 collection的内容需要使用Param中的别名来指定你需要用到的list或者array